I recently ran into a scenario where I needed to script the installation of a site extension into an existing Azure Web App. Typically, I would use an Azure ARM deployment to accomplish this but in this particular situation that wasn’t going to work.
I wanted to install the site extension that enables Application Insights Monitoring of a live website. After digging into existing arm templates, I found the name of that extension is Microsoft.ApplicationInsights.AzureWebSites.
After searching for way too long, I eventually found PowerShell command I needed on a forum somewhere. I can’t find it again so I’m posting this here in hopes that it will be easier for others to find in the future.
Installing a site extension to an existing App Service Web App
Installing a site extension to a Web App Deployment Slot
The scenario I ran into was actually attempting to add this site extension to a deployment slot. When you create a deployment slot, it doesn’t copy over any existing site extensions, which is a problem because when you swap your new slot to production, your new production slot ends up losing the site extensions that were in the old production slot.
This is a part of a series of blog posts on data access with Dapper. To see the full list of posts, visit the Dapper Series Index Page.
Update: April 16, 2018 Something really cool happened in the comments. The amazing Phil Bolduc very kindly pointed out that the query I wrote was not optimal and as a result, my benchmarks were not showing the best results. He didn’t stop there, he also submitted a pull request to the sample repo so I could rerun my benchmarks. Great job Phil and thanks a ton for being constructive in the comments section! I have updated the post to include Phil’s superior query.
In today’s post, we look at another option for how to load Many-to-One relationships. In the last post, we used a technique called Multi-Mapping to load related Many-to-One entities. In that post, I had a theory that maybe this approach was not the most efficient method for loading related entities because it duplicated a lot of data.
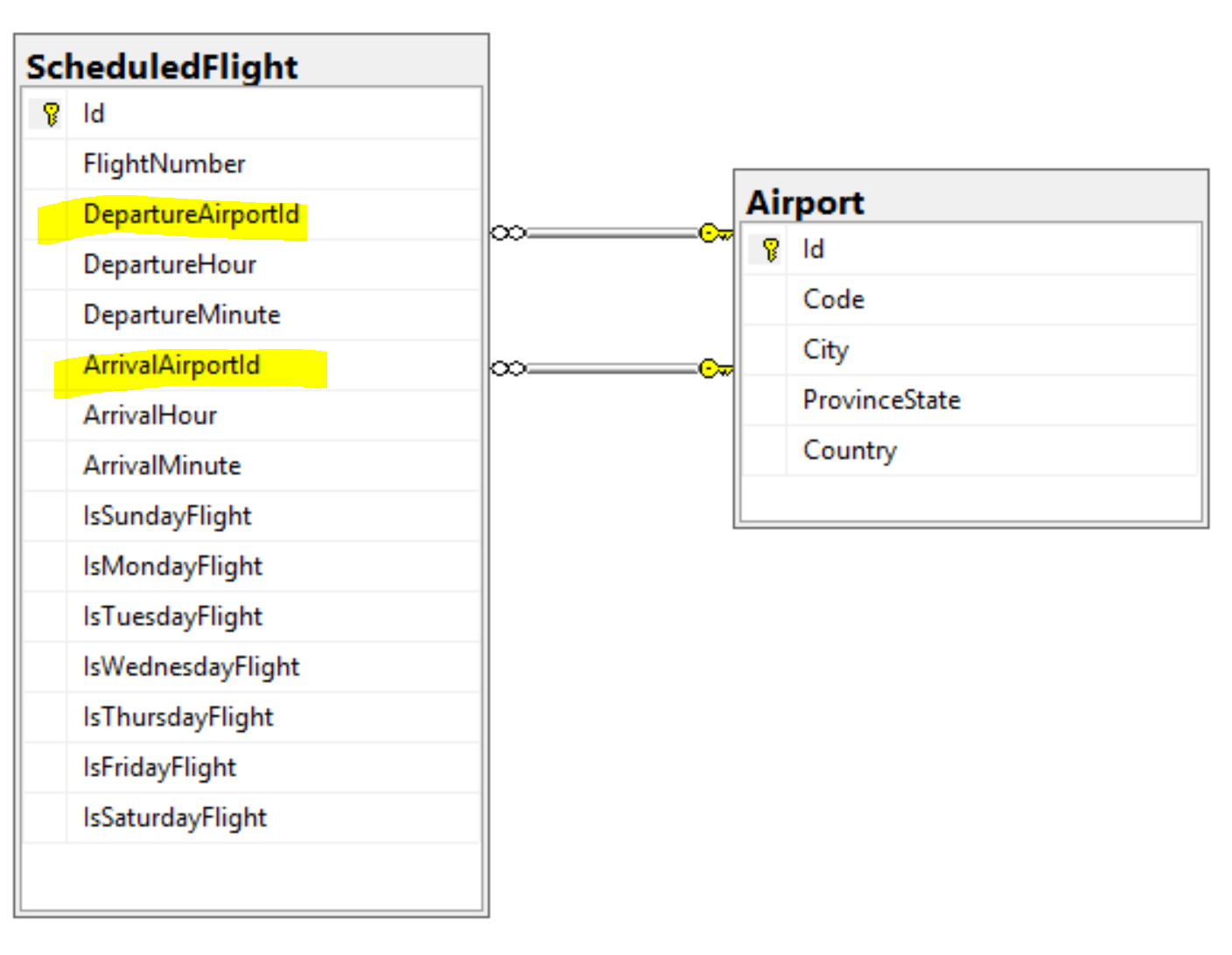
To recap, we would like to load a list of ScheduledFlight entities. A ScheduleFlight has a departure Airport and an arrival Airport.
publicclassScheduledFlight { publicint Id {get; set;} publicstring FlightNumber {get; set;}
publicclassAirport { publicint Id {get; set;} publicstring Code {get; set;} publicstring City {get; set;} publicstring ProvinceState {get; set;} publicstring Country {get; set;} }
Using Multiple Result Sets
In the previous post, we loaded the ScheduledFlight entities and all related Airport entities in a single query. In this example we will use 2 separate queries: One for the ScheduledFlight entities, one for the related arrival and departure Airport entities. These 2 queries will all be executed as a single sql command that returns multiple result sets.
SELECT s.Id, s.FlightNumber, s.DepartureHour, s.DepartureMinute, s.ArrivalHour, s.ArrivalMinute, s.IsSundayFlight, s.IsMondayFlight, s.IsTuesdayFlight, s.IsWednesdayFlight, s.IsThursdayFlight, s.IsFridayFlight, s.IsSaturdayFlight, s.DepartureAirportId, s.ArrivalAirportId FROM ScheduledFlight s INNERJOIN Airport a1 ON s.DepartureAirportId = a1.Id WHERE a1.Code = @FromCode SELECT Airport.Id, Airport.Code, Airport.City, Airport.ProvinceState, Airport.Country FROM Airport WHERE Airport.Id = @DepartureAirportId OR Airport.IdIN (SELECT s.ArrivalAirportId FROM ScheduledFlight s WHERE s.DepartureAirportId = @DepartureAirportId)
Using Dapper’s QueryMultipleAsync method, we pass in 2 arguments: the query and the parameters for the query.
publicasync Task<IEnumerable<ScheduledFlight>> GetAlt(stringfrom) { IEnumerable<ScheduledFlight> scheduledFlights; using (var connection = new SqlConnection(_connectionString)) { await connection.OpenAsync(); var query = @" SELECT s.Id, s.FlightNumber, s.DepartureHour, s.DepartureMinute, s.ArrivalHour, s.ArrivalMinute, s.IsSundayFlight, s.IsMondayFlight, s.IsTuesdayFlight, s.IsWednesdayFlight, s.IsThursdayFlight, s.IsFridayFlight, s.IsSaturdayFlight, s.DepartureAirportId, s.ArrivalAirportId FROM ScheduledFlight s INNER JOIN Airport a1 ON s.DepartureAirportId = a1.Id WHERE a1.Code = @FromCode SELECT Airport.Id, Airport.Code, Airport.City, Airport.ProvinceState, Airport.Country FROM Airport WHERE Airport.Id = @DepartureAirportId OR Airport.Id IN (SELECT s.ArrivalAirportId FROM ScheduledFlight s WHERE s.DepartureAirportId = @DepartureAirportId)";
using (var multi = await connection.QueryMultipleAsync(query, new{FromCode = from} )) { scheduledFlights = multi.Read<ScheduledFlight>(); var airports = multi.Read<Airport>().ToDictionary(a => a.Id); foreach(var flight in scheduledFlights) { flight.ArrivalAirport = airports[flight.ArrivalAirportId]; flight.DepartureAirport = airports[flight.DepartureAirportId]; }
} } return scheduledFlights; }
The QueryMultipleAsync method returns a GridReader. The GridReader makes it very easy to map multiple result sets to different objects using the Read<T> method. When you call the Read<T> method, it will read all the results from the next result set that was returned by the query. In our case, we call Read<ScheduledFlight> to read the first result set and map the results into a collection of ScheduledFlight entities. Next, we call Read<Airport> to read the second result set. We then call ToDictionary(a => a.Id) to populate those Airport entities into a dictionary. This is to make it easier to read the results when setting the ArrivalAirport and DepartureAirport properties for each ScheduledFlight.
Finally, we iterate through the scheduled flights and set the ArrivalAirport and DepartureAirport properties to the correct Airport entity.
The big difference between this approach and the previous approach is that we no longer have duplicate instances for Airport entities. For example, if the query returned 100 scheduled flights departing from Calgary (YYC), there would be a single instance of the Airport entity representing YYC, whereas the previous approach would have resulted in 100 separate instances of the Airport entity.
There is also less raw data returned by the query itself since the columns from the Airport table are not repeated in each row from the ScheduleFlight table.
Comparing Performance
I had a theory that the multi-mapping approach outlined in the previous blog post would be less efficient than the multiple result set approach outlined in this blog post, at least from a memory usage perspective. However, a theory is just theory until it is tested. I was curious and also wanted to make sure I wasn’t misleading anyone so I decided to test things out using Benchmark.NET. Using Benchmark.NET, I compared both methods using different sizes of data sets.
I won’t get into the details of Benchmark.NET. If you want to dig into it in more detail, visit the official site and read through the docs. For the purposes of this blog post, the following legend should suffice:
Mean : Arithmetic mean of all measurements Error : Half of 99.9% confidence interval StdDev : Standard deviation of all measurements Gen 0 : GC Generation 0 collects per 1k Operations Gen 1 : GC Generation 1 collects per 1k Operations Gen 2 : GC Generation 2 collects per 1k Operations Allocated : Allocated memory per single operation(managed only, inclusive, 1KB = 1024B)
10 ScheduledFlight records
Method
Mean
Error
StdDev
Gen 0
Allocated
MultiMapping
397.5 us
3.918 us
4.192 us
5.8594
6.77 KB
MultipleResultSets
414.2 us
6.856 us
6.077 us
4.8828
6.69 KB
As I suspected, the difference is minimal when dealing with small result sets. The results here are in microseconds so in both cases, executing the query and mapping the results takes less 1/2 a millisecond. The multiple result sets approach takes a little longer, which I kind of expected because of the overhead of creating a dictionary and doing lookups into that dictionary when setting the ArrivalAirport and DepartureAirport properties. The difference is minimal and in a most real world scenarios, this won’t be noticeable. What is interesting is that even with this small amount of data, we can see that there is ~1 more Gen 0 garbage collection happening per 1,000 operations. I suspect we will see this creep up as the amount of data increases.
100 ScheduledFlight records
Method
Mean
Error
StdDev
Gen 0
Allocated
MultiMapping
926.5 us
21.481 us
32.804 us
25.3906
6.77 KB
MultipleResultSets
705.9 us
7.543 us
7.056 us
15.6250
6.69 KB
When mapping 100 results, the multiple result sets query is already almost 25% faster. Keep in mind though that both cases are still completing in less than 1ms so this is very much still a micro optimization (pun intended). Either way, less than a millisecond to map 100 records is crazy fast.
1000 ScheduledFlight records
Method
Mean
Error
StdDev
Gen 0
Gen 1
Allocated
MultiMapping
5.098 ms
0.1135 ms
0.2720 ms
148.4375
70.3125
6.77 KB
MultipleResultSets
2.809 ms
0.0549 ms
0.0674 ms
109.3750
31.2500
6.69 KB
Here we go! Now the multiple result sets approach finally wins out, and you can see why. There are way more Gen 0 and Gen 1 garbage collections happening per 1,000 operations when using the multi-mapping approach. As a result, the multiple result sets approach is nearly twice as fast as the multi mapping approach.
10,000 ScheduledFlight records
Method
Mean
Error
StdDev
Gen 0
Gen 1
Gen 2
Allocated
MultiMapping
56.08 ms
1.5822 ms
1.4026 ms
1687.5000
687.5000
187.5000
6.78 KB
MultipleResultSets
24.93 ms
0.1937 ms
0.1812 ms
843.7500
312.5000
125.0000
6.69 KB
One last test with 10,000 records shows a more substantial difference. The multiple result sets approach is a full 22ms faster!
Wrapping it up
I think that in most realistic scenarios, there is no discernable difference between the 2 approaches to loading many-to-one related entities. If you loading larger amounts of records into memory in a single query, then the multiple result sets approach will likely give you better performance. If you are dealing with < 100 records per query, then you likely won’t notice a difference. Keep in mind also that your results will vary depending on the specific data you are loading.
This is a part of a series of blog posts on data access with Dapper. To see the full list of posts, visit the Dapper Series Index Page.
In today’s post, we will start our journey into more complex query scenarios by exploring how to load related entities. There are a few different scenarios to cover here. In this post we will be covering the Many-to-One scenario.
Continuing with our sample domain for the ever expanding Air Paquette airline, we will now look at loading a list of ScheduledFlight entities. A ScheduleFlight has a departure Airport and an arrival Airport.
publicclassScheduledFlight { publicint Id {get; set;} publicstring FlightNumber {get; set;}
publicclassAirport { publicint Id {get; set;} publicstring Code {get; set;} publicstring City {get; set;} publicstring ProvinceState {get; set;} publicstring Country {get; set;} }
Side Note: Let’s ignore my poor representation of the arrival and departure times of the scheduled flights. In a future most we might look using Noda Time to properly represent these values.
Loading everything in a single query
Using Dapper, we can easily load a list of ScheduledFlight using a single query. First, we need to craft a query that returns all the columns for a ScheduledFlight, the departure Airport and the arrival Airport in a single row.
We use the QueryAsync method to load a list of ScheduledFlight entities along with their related DepartureAirport and ArrivalAirport entities. The parameters we pass in are a little different from what we saw in our previous posts.
First, instead of a single type parameter <ScheduledFlight>, we need to provide a series of type parameters: <ScheduledFlight, Airport, Airport, ScheduledFlight>. The first 3 parameters specify the types that are contained in each row that the query returns. In this example, each row contains columns that will be mapped to ScheduledFlight and 2 Airports. The order matters here, and Dapper assumes that when it seems a column named Id then it is looking at columns for the next entity type. In the example below, the columns from Id to IsSaturdayFlight are mapped to a ScheduledFlight entity. The next 5 columns Id, Code, City, ProvinceState, Country are mapped to an Airport entity, and the last 5 columns are mapped to a second Airport entity. If you aren’t using Id, you can use the optional splitOn argument to specify the column names that Dapper should use to identity the start of each entity type.
What’s that last type parameter? Why do we need to specify ScheduledFlight again? Well, I’m glad you asked. The thing about Dapper is that it doesn’t actually know much about the structure of our entities so we need to tell it how to wire up the 3 entities that it just mapped from a row. That last ScheduledFlight type parameter is telling Dapper that ScheduledFlight is ultimately the entity we want to return from this query. It is important for the second argument that is passed to the QueryAsync method.
That second argument is a function that takes in the 3 entities that were mapped back from that row and returns and entity of the type that was specified as the last type parameter. In this case, we assign the first Airport to the flight’s DepartureAirport property and assign the second Airport to the flight’s ArrivalAiport parameter, then we return the flight that was passed in.
The first argument argument passed to the QueryAsync method is the SQL query, and the third argument is an anonymous object containing any parameters for that query. Those arguments are really no different than the simple examples we saw in previous blog posts.
Wrapping it up
Dapper refers to this technique as Multi Mapping. I think it’s called that because we are mapping multiple entities from each row that the query returns. In a fully featured ORM like Entity Framework, we call this feature Eager Loading. It is an optimization technique that avoids the need for multiple queries in order to load an entity and it’s associated entities.
This approach is simple enough to use and it does reduce the number of round trips needed to load a set of entities. It does, however, come at a cost. Specifically, the results of the query end up causing some duplication of data. As you can see below, the data for the Calgary and Vancouver airports is repeated in each row.
This isn’t a huge problem if the result set only contains 3 rows but it can become problematic when dealing with large result sets. In addition to creating somewhat bloated result sets, Dapper will also create new instances of those related entities for each row in the result set. In the example above, we would end up with 3 instances of the Airport class representing YYC - Calgary and 3 instances of the Airport class representing YVR - Vancouver. Again, this isn’t necessarily a big problem when we have 3 rows in the result set but with larger result sets it could cause your application to use a lot more memory than necessary.
It is worth considering the cost associated with this approach. Given the added memory cost, this approach might be better suited to One-to-One associations rather than the Many-to-One example we talked about in this post. In the next post, we will explore an alternate approach that is more memory efficient but probably a little more costly on the CPU for the mapping.
This is a part of a series of blog posts on data access with Dapper. To see the full list of posts, visit the Dapper Series Index Page.
Let’s just get this one out of the way early. Stored procedures are not my favorite way to get data from SQL Server but there was a time when they were extremely popular. They are still heavily used today and so this series would not be complete without covering how to use stored procedures with Dapper.
A Simple Example
Let’s imagine a simple stored procedure that allows us to query for Aircraft by model.
CREATEPROCEDURE GetAircraftByModel @ModelNVARCHAR(255) AS BEGIN SELECT Id ,Manufacturer ,Model ,RegistrationNumber ,FirstClassCapacity ,RegularClassCapacity ,CrewCapacity ,ManufactureDate ,NumberOfEngines ,EmptyWeight ,MaxTakeoffWeight FROM Aircraft a WHERE a.Model = @Model END
To execute this stored procedure and map the results to a collection of Aircraft objects, use the QueryAsync method almost exactly like we did in the last post.
Instead of passing in the raw SQL statement, we simply pass in the name of the stored procedure. We also pass in an object that has properties for each of the stored procedures arguments, in this case new {Model = model} maps the model variable to the stored procedure’s @Model argument. Finally, we specify the commandType as CommandType.StoredProcedure.
Wrapping it up
That’s all there is to using stored procedures with Dapper. As much as I dislike using stored procedures in my applications, I often do have to call stored procedures to fetch data from legacy databases. When that situation comes up, Dapper is my tool of choice.
Stay tuned for the next installment in this Dapper series. Comment below if there is a specific topic you would like covered.
I was recently asked to create a read-only web API to expose some parts of a system’s data model to third party developers. While Entity Framework is often my go-to tool for data access, I thought this was a good scenario to use Dapper instead. This series of blog posts explores dapper and how you might use it in your application. To see the full list of posts, visit the Dapper Series Index Page.
Today, we will start with the basics of loading a mapping and database table to a C# class.
What is Dapper?
Dapper calls itself a simple object mapper for .NET and is usually lumped into the category of micro ORM (Object Relational Mapper). When compared to a fully featured ORM like Entity Framework, Dapper lacks certain features like change-tracking, lazy loading and the ability to translate complex LINQ expressions to SQL queries. The fact that Dapper is missing these features is probably the single best thing about Dapper. While it might seem like you’re giving up a lot, you are also gaining a lot by dropping those types of features. Dapper is fast since it doesn’t do a lot of the magic that Entity Framework does under the covers. Since there is less magic, Dapper is also a lot easier to understand which can lead to lower maintenance costs and maybe even fewer bugs.
How does it work?
Throughout this series we will build on an example domain for an airline. All airlines need to manage a fleet of aircraft, so let’s start there. Imagine a database with a table named Aircraft and a C# class with property names that match the column names of the Aircraft table.
Dapper is available as a Nuget package. To use Dapper, all you need to do is add the Dapper package to your project.
.NET Core CLI: dotnet add package Dapper
Package Manager Console: Install-Package Dapper
Querying a single object
Dapper provides a set of extension methods for .NET’s IDbConnection interface. For our first task, we want to execute a query to return the data for a single row from the Aircraft table and place the results in an instance of the Aircraft class. This is easily accomplished using Dapper’s QuerySingleAsync method.
[HttpGet("{id}")] publicasync Task<Aircraft> Get(int id) { Aircraft aircraft; using (var connection = new SqlConnection(_connectionString)) { await connection.OpenAsync(); var query = @" SELECT Id ,Manufacturer ,Model ,RegistrationNumber ,FirstClassCapacity ,RegularClassCapacity ,CrewCapacity ,ManufactureDate ,NumberOfEngines ,EmptyWeight ,MaxTakeoffWeight FROM Aircraft WHERE Id = @Id";
Before we can call Dapper’s QuerySingleASync method, we need an instance of an open SqlConnection. If you are an Entity Framework user, you might not be used to working directly with the SqlConnection class because Entity Framework generally manages connections for you. All we need to do is create a new SqlConnection, passing in the connection string, then call OpenAsync to open that connection. We wrap the connection in a using statement to ensure that connection.Dispose() is called when we are done with the connection. This is important because it ensures the connection is returned to the connection pool that is managed by .NET. If you forget to do this, you will quickly run into problems where your application is not able to connect to the database because the connection pool is starved. Check out the .NET Docs for more information on connection pooling.
We will use the following pattern throughout this series of blogs posts:
using(var connection = new SqlConnection(_connectionString)) { await connection.OpenAsync(); //Do Dapper Things }
As @Disman pointed out in the comments, it is not necessary to call connection.OpenAsync(). If the connection is not already opened, Dapper will call OpenAsync for you. Call me old fashioned but I think that whoever created the connection should be the one responsible for opening it, that’s why I like to open the connection before calling Dapper.
Let’s get back to our example. To query for a single Aircraft, we call the QuerySingleAsync method, specifying the Aircraft type parameter. The type parameter tells Dapper what class type to return. Dapper will take the results of the query that gets executed and map the column values to properties of the specified type. We also pass in two arguments. The first is the query that will return a single row based on a specified @Id parameter.
SELECT Id ,Manufacturer ,Model ,RegistrationNumber ,FirstClassCapacity ,RegularClassCapacity ,CrewCapacity ,ManufactureDate ,NumberOfEngines ,EmptyWeight ,MaxTakeoffWeight FROM Aircraft WHERE Id = @Id
The next parameter is an anonymous class containing properties that will map to the parameters of the query.
new {Id = id}
Passing the parameters in this way ensures that our queries are not susceptible to SQL injection attacks.
That’s really all there is to it. As long as the column names and data types match the property of your class, Dapper takes care of executing the query, creating an instance of the Aircraft class and setting all the properties.
If the query doesn’t contain return any results, Dapper will throw an InvalidOperationException.
InvalidOperationException: Sequence contains no elements
If you prefer that Dapper returns null when there are no results, use the QuerySingleOrDefaultAsnyc method instead.
Querying a list of objects
Querying for a list of objects is just as easy as querying for a single object. Simply call the QueryAsync method as follows.
using (var connection = new SqlConnection(_connectionString)) { await connection.OpenAsync(); var query = @" SELECT Id ,Manufacturer ,Model ,RegistrationNumber ,FirstClassCapacity ,RegularClassCapacity ,CrewCapacity ,ManufactureDate ,NumberOfEngines ,EmptyWeight ,MaxTakeoffWeight FROM Aircraft"; aircraft = await connection.QueryAsync<Aircraft>(query); } return aircraft; }
In this case, the query did not contain any parameters. If it did, we would pass those parameters in as an argument to the QueryAsync method just like we did for the QuerySingleAsync method.
What’s next?
This is just the beginning of what I expect will be a long series of blog posts. You can follow along on this blog and you can track the sample code on GitHub.
Leave a comment below if there is a topic you would like me to cover.
I was recently asked to create a read-only web API to expose some parts of a system’s data model to third party developers. While Entity Framework is often my go-to tool for data access, I thought this was a good scenario to use Dapper instead.
In the coming weeks, I will be posting a series of blog posts exploring Dapper and how you might use it in your application. This page will act as the index for those posts. I will update the page here whenever a new post is available.