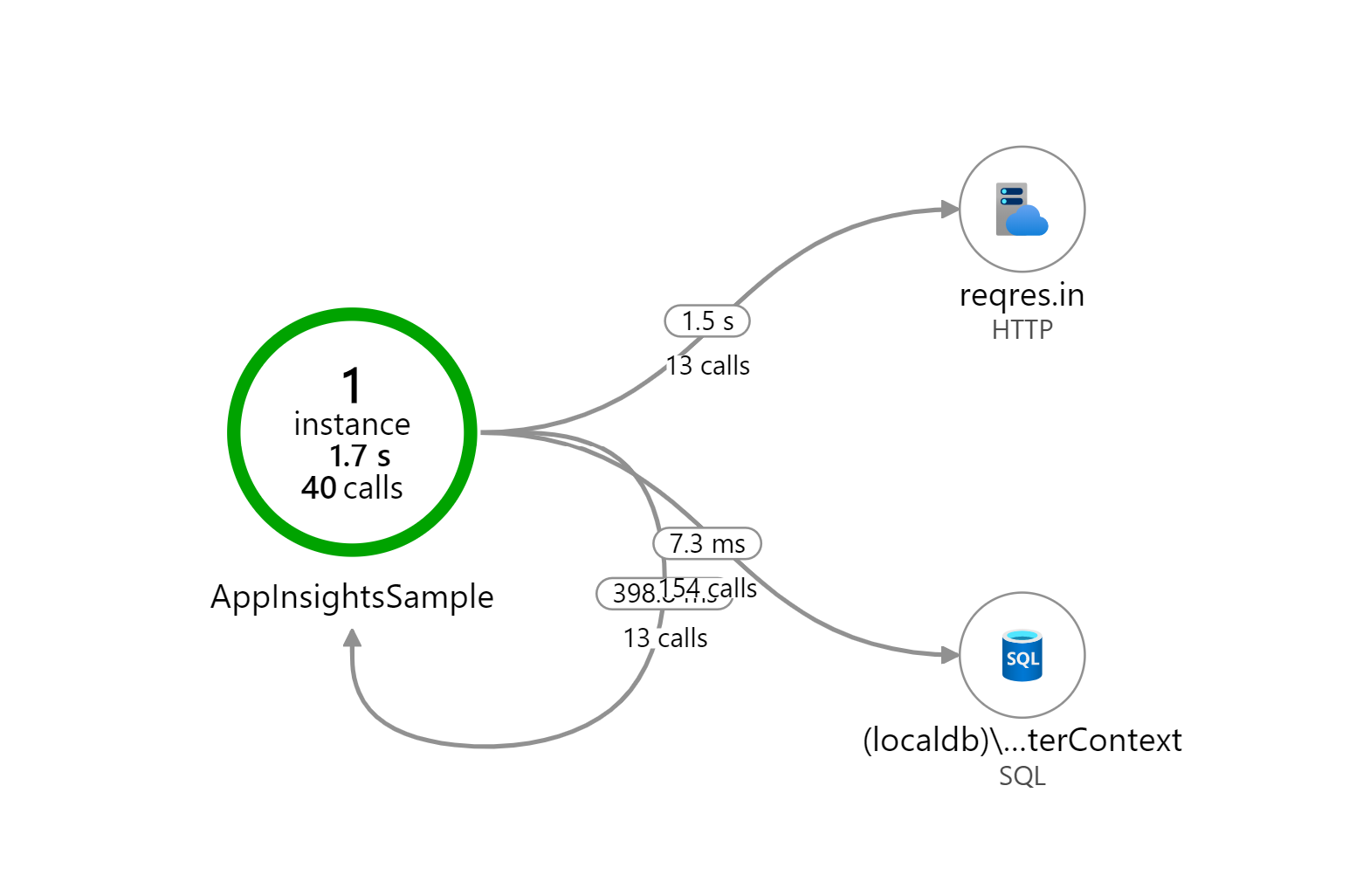
Azure Functions, when hosted on a consumption plan, are great for most scenarios. You pay per use which is great for keeping costs down but there are some downsides and limitations. One of those is the time it takes to cold start your function app. If your function app hasn’t been triggered in some time, it can take a while for the a new instance to start up to run your app. Likewise, if a very sudden spike in load occurs, it can take some time for the consumption plan to start up enough instances to handle that load. In the meantime, you might have clients getting timeouts or failed requests.
Azure Functions offers another hosting model called Azure Functions Premium Plan. With premium plans, instead of paying per function execution, you pay for the underlying compute instances that are hosting your functions. This is often more expensive, but it also ensures there are always a pre-set number of warmed instances ready to execute your function.
That’s great, but what if I only really need those pre-warmed instances for a short period of time when I’m expecting a lot of incoming traffic. The rest of the time, I would rather use a Consumption Plan to save on hosting costs.
I thought the choice of hosting plan was something you needed to make up front but it turns out that you can actually move an Azure Function App from a consumption plan to a premium plan (and back again).
Thanks to Simon Timms for starting this discussion on Twitter. We got very helpful responses from folks on the Azure Functions team:
Jeff Hollan has a great sample using an Azure Durable Function to scale an Azure Function App to a premium plan for a specified amount of time, then automatically scale back down to a consumption plan.
— Jeff Hollan (@jeffhollan) April 2, 2020
This is a super cool sample. It uses the Azure Resource Manager REST API to make changes to the target function app resources. For my project however, I didn’t really want to spin up another Azure Function to manage my Azure Functions. I just wanted an easy way to scale my 12 function apps up to premium plans for a couple hours, then scale them back down to a consumption plan.
I decided to try using the AZ CLI for this and it turned out really well. I was able to write a simple script to scale up and down.
Setting up the AZ CLI
First up, install the az cli.
Once installed, you’ll need to login to your Azure Subscription.
az login |
A browser window will popup, prompting you to log in to your Azure account. Once you’ve logged in, the browser window will close and the az cli will display a list of subscriptions available in your account. If you have more than one subscription, make sure you select the one you want to use.
az account set --subscription YourSubscriptionId |
Create a Resource Group
You will need a resource group for your Storage and CDN resources. If you don’t already have one, create it here.az group create --name DavesFunctionApps --location WestUS2
Most commands will require you to pass in a --resource-group and --location parameters. These parameters are -g and -l for short, but you can save yourself even more keystrokes by setting defaults for az.
az configure -d group=DavesFunctionApps |
Creating a (temporary) Premium Hosting Plan
There is a strange requirement with Azure Functions / App Service. As per Jeff Hollan’s sample:
The Azure Functions Premium plan is only available in a sub-set of infrastructure in each region. Internally we call these “webspaces” or “stamps.” You will only be able to move your function between plans if the webspace supports both consumption and premium. To make sure your consumption and premium functions land in an enabled webspace you should create a premium plan in a new resource group. Then create a consumption plan in the same resource group. You can then remove the premium plan. This will ensure the consumption function is in a premium-enabled webspace.
First, add an Azure Functions Premium plan to the resource group.az functionapp plan create -n dave_temp_premium_plan --sku EP1 --min-instances 1
You can delete this premium plan using the command below after you’ve deployed a function app to this resource group . Don’t forget to delete the premium plan. These cost $$$
az functionapp plan delete -n dave_temp_premium_plan |
Creating a Function App
There are many options for creating a new function app. I really like the func command line tool which I installed using npm. Check out the Azure Functions Core Tools GitHub Repo for details on other options for installing the func tooling.
npm i -g azure-functions-core-tools@3 --unsafe-perm true |
The focus of this blog post is around scaling a function app. If you don’t already have an app built, you can follow along with this walkthrough to create a function app.
A function app requires a Storage Account resource. An Application Insights resource is also highly recommended as this really simplifies monitoring your function app after it has been deployed. Let’s go ahead and create those 2 resources.
az storage account create -n davefuncappstorage |
Now we can create our Azure Function App resource with a consumption plan, passing in the name of the storage account and app insights resources that we just created. In my case, I’m specifying the dotnet runtime on a Windows host.
az functionapp create --consumption-plan-location WestUS2 --name davefuncapp123 --os-type Windows --runtime dotnet --storage-account davefuncappstorage --app-insights davefuncappinsights --functions-version 3 |
Remember to delete that temporary Premium Hosting Plan now!
az functionapp plan delete -n dave_temp_premium_plan |
Deploying your Function App using the az cli
This is a bit outside the scope of this blog post but I like using the az cli to deploy my function apps because it’s easy to incorporate that into my CI/CD pipelines. Since my app is using the dotnet runtime, I use the dotnet publish command to build the app.
dotnet publish -c release |
Then, zip the contents of the publish folder (bin\release\netcoreapp3.1\publish\).
In PowerShell:Compress-Archive -Path .\bin\release\netcoreapp3.1\publish\* -DestinationPath .\bin\release\netcoreapp3.1\package.zip
or in Bash
zip -r ./bin/release/netcoreapp3.1/package.zip ./bin/release/netcoreapp3.1/publish/ |
Finally, use the az functionapp deployment command to deploy the function app.
az functionapp deployment source config-zip -n davefuncapp123 --src ./bin/release/netcoreapp3.1/package.zip |
Scale up to a premium plan
Okay, now that we have a functioning (pun intended) app deployed and running on a consumption plan, let’s see what it takes to scale this thing up to a premium plan.
First, create a new Premium Hosting Plan with the parameters that make sense for the load you are expecting. The --sku parameter refers to the size of the compute instance: EP1 is the smallest. The --min-instancs parameter is the number of pre-warmed instances that will always be running for this hosting plan. The --max-burst parameter is the upper bounds on the number of instances that the premium plan can elastically scale out if more instances are needed to handle load.
az functionapp plan create -n davefuncapp123_premium_plan --sku EP1 --min-instances 4 --max-burst 12 |
Next, move the function app to that premium hosting plan.
az functionapp update --plan davefuncapp123_premium_plan -n davefuncapp123 |
That’s it! All it took was those 2 command and your function app is now running on a premium plan!
Scale back down to a consumption plan
Of course, that premium plan isn’t cheap. You might only want your function app running on the premium plan for a short period of time. Scaling back down is equally easy.
First, move the function app back to the consumption based plan. In my case, the name of the consumption plan is WestUS2Plan. You should see a consumption plan in your resource group.
az functionapp update --plan WestUS2Plan -n davefuncapp123 |
Next, delete the premium hosting plan.
az functionapp plan delete -n davefuncapp123_premium_plan |
Wrapping it up
In this post, we saw how easy it is to move a function app between Premium and Consumption plans. A couple very simple az commands can help you get the performance and features of the Premium plan only when you need it while taking advantages of the simplicity and cost savings of a Consumption plan the rest of the time.